“记录一下自己用yolov1的tiny-yolo做car检测的整个过程”
训练数据集准备
数据集用的是KITTI object detection 数据集,参考SqueezeDet. 下载链接:image和labels, 估计得下载一会儿. 解压出来, 你可以获得两个目录: KITTI/training/ 和 KITTI/testing.
接下来,我们想做的是, 把图片的名称(不包括后缀名), 都写到一个txt文件中, 方便我们后边调用(比方说分成训练集和测试集).
cd $ROOT/data/KITTI/
mkdir ImageSets
cd ./ImageSets
ls ../training/image_2/ | grep ".png" | sed s/.png// > trainval.txt
这里继续按照SqueezeDet里面的做法用random_split_train_val.py把trainval.txt分成两个文件train.txt和val.txt. 数据集的组织形式就是:
$ROOT/data/KITTI/
|->training/
| |-> image_2/00****.png
| L-> label_2/00****.txt
|->testing/
| L-> image_2/00****.png
L->ImageSets/
|-> trainval.txt
|-> train.txt
L-> val.txt
因为要用yolov1来训练kitti, 而yolov1原本是支持VOC格式的数据集的, 所以接下来就是要把kitti数据集转成VOC格式的数据集, 非常幸运的是已经有大神给我们写好工具了, 即vod-converter, 你只要运行它提供的命令, 就可以将kitti数据集转成voc格式的数据集. 它是用python3.6写的, 而我的电脑装的python2.7, 幸运的是, 在它的README的最下面也提供了python2.7的实现vod-converter-py2.7.
将代码下载到本地, 需要注意要将上面生成的trianval.txt文件改成train.txt拷贝到KITTI目录下(因为我们需要将所有的训练数据集都变成VOC格式的) ,即与training和testing平级的位置. 然后运行下面给的代码就可以了. 这里需要将--from-path和--to-path后面的内容修改成你自己的路径就行了.
$ python vod_converter/main.py --from kitti --from-path data/KITTI --to voc --to-path data/kitti-voc
在转的时候碰到些问题, 记录下来. 参考here
question 1: ““%s/%d.%s” % (images_path, image_id, src_extension)) TypeError: %d format: a number is required, not str”
solution: 将image_id对应的”%d”都改成了”%s”, 因为image_id本身就是个字符串.
question 2: “cannot serialize %r (type %s)” % (text, type(text).name)”
solution: 在voc.py 178行, 将subnode.text = text 改成 subnode.text = str(text)
这时候会在/kitti-voc/VOC2012/ImageSets/Main 下面生成一个trainval.txt文件, 我们需要将上面生成的train.txt和val.txt文件都放到这, 并将val.txt改成test.txt. 还将目录中的VOC2012改成了VOC2007了.
数据集准备就完成了.
修改yolov1代码
接下来就是修改yolov1的代码来适配我们的这个数据集了, 其实修改量没多大. 主要工作量其实是上面数据集转换过程.
yolov1的来源
现在yolo官网给的代码是yolov2的.
而将网页拉到最后进入yolov1的页面之后, 其实没找到他之前的yolov1的代码. 估计是代码后面改进了, 只剩下现在的darknet的代码了. 区别是比方说原先的yolo.c 文件就放到src/文件夹下, 现在却放到了examples/文件夹下面了. 其实不重要, yolov2的代码也是一样用. 但我还是不死心, 就想用原来的 yolov1的代码.
找了很久, 找到了一个用yolov1实现人脸检测的项目, 感觉很不错, 他里面用的就是yolov1的代码. 我后面的做car检测也是参考着他的工作来的.
少啰嗦, 先把这个项目下载到本地再说.
他这个项目做的人脸检测, 他把他自己的一些配置文件都放到了models/文件夹下面了. 比较重要的也是我需要用的就是models/yolo-face.cfg和darknet.conv.weights这两个文件了. 按照他在yotube上的回答来说它这个yolo-face.cfg其实是I adjust the connected layer output to "[connected] output= 1331" . 而darknet.conv.weights是 I download the "Darknet Reference Model" 28MB and extract the conv weights with "./darknet partial cfg/darknet.cfg ~/trained/darknet.weights darknet.conv.weights 14"
这里解释一下这两个文件是怎么来的
首先是yolo-face.cfg
它应该是基于cfg/yolo-tiny.cfg 修改的, 主要是将yolo-tiny.cfg里面的batch, learning_rate以及最后的output, classes, side改了, 最后的classes改成了1, 因为他只做人脸检测, 就只有一类. side改成了11, 原本应该是7, 这个估计是因为人脸比较小, 想要yolov1检测的更精细一点, 所以改成了11. 而output=(5 x num + classes) x side x side, 也就是1331了. 后面我的car检测也就是直接把他的东西拿过来用了.
然后是darknet.conv.weights
这个文件就像作者说的一样, 是提取了cfg/darknet.cfg前面的conv层权重, 用于为后面训练yolo-face.cfg网络初始化权重用. 而他命令中的~/trined/darknet.weights就是他提前下载好的Darknet Reference Model(应该是这个文件). 运行上面的命令./darknet partial cfg/darknet.cfg ~/trained/darknet.weights darknet.conv.weights 14就会得到了.
修改yolov1适配我们的kitti数据集
首先我们把上面准备好的kitti数据集放到darknet/data/下面.
这里按照官网, 还需要做一个工作, 就是把VOC的标注文件转成darknet可以读取的格式. 按照官网来就行.
将scripts/voc_label.py也放到darknet/data/kitti/下面,和VOCdevkit目录同级.
修改一下voc_label.py文件, 将line 7 的sets=[('2012', 'train'), ('2012', 'val'), ('2007', 'train'), ('2007', 'val'), ('2007', 'test')]改成sets=[('2007', 'train'), ('2007', 'test')]. 因为我们在VOCdevkit/VOC2007/ImageSets/Main/下面只有这两个数据集. 再将line 10 的classes=["person"] 改成classes=["car"]. 保存退出. 运行python voc_label.py就行了. 会在当前目录生成两个文件2007_train.txt和2007_test.txt里面就是文件路径, 同时在VOCdevkit/VOC2007/目录下面还会生成一个labels/目录,用于存放标注文件.
数据集的标注都准备好了, 下面开始修改src/yolo.c文件. 打开src/yolo.c文件.
先看line 15, char *voc_names[] = {"face"};, 改成char *voc_names[] = {"car"};,
然后是line 20, 21, 将train_images路径改成自己的kitti数据集的路径,一直写到2007_train.txt就行了,注意是绝对路径.
还有backup_directory是用来存放模型的, 自己写一个就行.
这里还有一处需要注意的是, 因为我们用的是kitti数据集, 图片格式是png格式的, 而voc是jpg格式的. 所以有一个地方还得改一下, 就是src/data.c下的fill_truth_region函数里面labelpath = find_replace(labelpath, ".jpg", ".txt");, 将这个.jpg全换成.png, 包括下面两行, 也对应换.
上面的工作做完, 就可以开始训练了.
训练
因为是c语言写的, 所以需要Make, 先看一下MakeFile文件, 因为我的电脑本身是带GPU, 而且和作者的一样是Titan X的, 所以不需要修改, 如果有不一样的话, 需要修改一下ARCH= --gpu-architecture=compute_52 --gpu-code=compute_52这里.
训练:
./darknet yolo train models/yolo-face.cfg models/darknet.conv.weights
我训练了差不多一天半, 损失值从66一直下载到4左右就不下降了,我就ctrl+c中断了. 而Avg IOU也从0.0000左右一直到0.5左右.
检测
检测数据是从kitti的testing文件夹下拿出来的.比方说000001.png.
检测:
./darknet yolo test model/yolo-face.cfg yolo-car_33000.weights data/000002.png
这个yolo-car-final.weights就是你最后训练得到的.
插一张最后的检测图
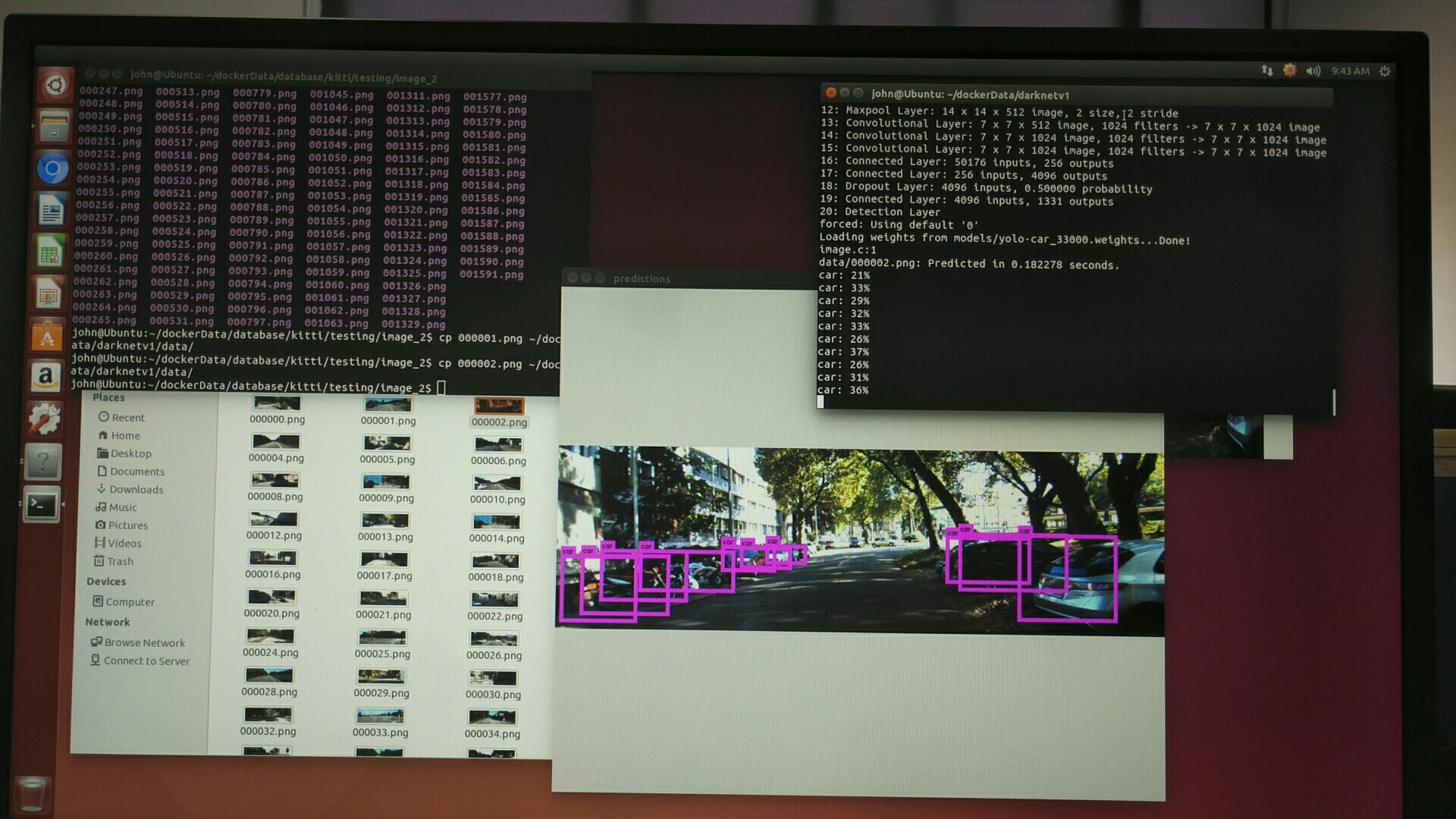
从图上看, 还是有一些效果的, 就是检测精度不高, 因为这是yolov1的tiny-yolo, 效果没那么好, 后面可以试试yolov2的tiny-yolo. 效果应该会更好一些.
后记
也可以参考我的github
想把这个权重值换成tensorflow的.ckpt格式的, 再用python+tensorflow版本的再跑一遍.