书接上文,将上文中得到的darknet.weights转成tensorflow的.ckpt格式的文件,再用tensorflow的代码再做一次检测
前言
主要用到了以下几个github的代码:
- YOLO_tensorflow,这个的作用是将darknet.weights转成xxxx.ckpt,当然这个仓库里面也有一个可以做检测的代码,但没有训练的代码
- yolo_tensorflow, 这个是yolov1的tensorflow的实现版, 可以做训练也可以做检测
正文
将darknet.weights转成darknet.ckpt
先将YOLO_tensorflow代码download下来,YOLO_weight_extractor/目录里面的README也是有介绍,我也是按照来的. 将里面的YOLO_weight_extractior.tar.gz解压出来. 好了,下面按照步骤来吧:
- 将
darknet.weights放到当前目录下(有darknet的执行文件的目录) - 运行
./darknet yolo test cfg/yolo-tiny.cfg darknet.weights,(这个yolo-tiny.cfg就是上一篇文件中训练的时候使用的文件, 这个darknet.weights也是用这个cfg文件训练得到的) - 他这个命令会把你
darknet.weights里面的东西以.txt的格式存到当前目录下的cjy/目录下 - 现在权重信息全都按层转成了.txt文件了,现在我们要把这些文件变成.ckpt的. 打开
YOLO_tiny_builder.py, 将line 6的weight_dir改成'cjy/'(也就是包含刚才转换好了的权重信息的那个文件夹). 同时,看看build_networks()函数里面的网络层次结构是否和你的yolo-tiny.cfg文件中的结构对的上. 这里我们需要它对的上, 因为我们是要拿转换好的.ckpt文件直接去做检测的. 如果你只想要前面的卷积层的权重去做训练, 在build_networks()里的网络结构可以只写到卷积层, 那最后输出的也就只有卷积层的权重了,也就可以拿去继续训练了. - 当然紧挨着weight_dir下面的是
out_file,这个也要改一下,我改成了model/YOLO_car_tiny.ckpt,当然你首先得自己创建一个model文件夹,要不会报错 - 直接
python YOLO_tiny_builder.py就可以了,程序就会把权重信息转成.ckpt格式的了.
还有一点想说一下:
你看这个YOLO_tiny_builder.py里面构建网络用的是自己定义的conv_layer()和fc_layer, 再看函数里面的weight和biases变量, 在声明的时候是没有起名字的. 因为我后边想用上面提到的yolo_tensorflow这个代码做检测,而在这个代码中,网络结构是用slim定义的,每一层的weight和biases是有名字的. 所以呢我在转换的时候呢, 特意给weight和biases起了相同的名字,方便后面被restore:
conv_layer():
weight = tf.Variable(w,name='yolo/conv_'+str(idx)+'/weights')
biases = tf.Variable(l_b.reshape((filters)), name='yolo/conv_'+str(idx)+'/biases')
fc_layer():
weight = tf.Variable(w, name='yolo/fc_'+str(idx)+'/weights')
biases = tf.Variable(l_b.reshape((hiddens)), name='yolo/fc_'+str(idx)+'/biases')
好了,现在转换完了,转换好的权重存到了model/YOLO_car_tiny.ckpt里面了,下面要用这个权重做检测了
检测(方法一)
现在从YOLO_weight_extractor目录往回退,一直退到YOLO_tensorflow/目录下, 将刚才转换好的YOLO_car_tiny.ckpt(包含3个文件,YOLO_car_tiny.ckpt.data-00000-of-00001,YOLO_car_tiny.ckpt.index,YOLO_car_tiny.ckpt.meta)copy到现在的weights/目录下,下面在修改一下YOLO_tiny_tf.py文件:
1. line 15: weights_file = 'weights/YOLO_car_tiny.ckpt'
2. line 17: threshold = 0.1 #本来是0.2的,后边检测出来,如果是0.2的话就没有框了,所以改小一点,这个直接拿来用是有点问题
3. line 19: num_class = 1 #因为只做了car的检测,只有一类
4. line 21: grid_size = 11
5. line 22: classes = ["car"]
6. line 64: self.fc_19 = self.fc_layer(19,self.fc_17,1331,flat=False,linear=True) #这个输出还是要对应上
7. line 73: weight = tf.Variable(tf.truncated_normal([size,size,int(channels),filters], stddev=0.1), name='yolo/conv_'+str(idx)+'/weights') #同样,是为了把名字对应上
8. line 74: biases = tf.Variable(tf.constant(0.1, shape=[filters]), name='yolo/conv_'+str(idx)+'/biases')
9. line 99: weight = tf.Variable(tf.truncated_normal([dim,hiddens], stddev=0.1), name='yolo/fc_'+str(idx)+'/weights')
10. line 100:biases = tf.Variable(tf.constant(0.1, shape=[hiddens]), name='yolo/fc_'+str(idx)+'/biases')
还有line 142: interpret_output()函数里面也有一些地方需要改动, 主要是因为,我们把7x7变成了11x11了
1. line 143: probs = np.zeros((11,11,2,1)) #11x11的格子,2个框框,1个类
2. line 144: class_probs = np.reshape(output[0:121],(11,11,1)) #前121个数,代表的是类别概率
3. line 145: scales = np.reshape(output[121:363],(11,11,2)) #接下来的242个数, 代表的是框框的得分
4. line 146: boxes = np.reshape(output[363:],(11,11,2,4))
5. line 147: offset = np.transpose(np.reshape(np.array([np.arange(11)]\*22),(2,11,11)),(1,2,0)) #表示的偏移,因为yolo预测的是坐标值都是偏移值,这样方便预测,所以做检测的时候得加上各自的偏移值才是最终的坐标值
6. line 151: boxes[:,:,:,0:2] = boxes[:,:,:,0:2] / 11.0
好了,没什么问题了,从kitti检测数据集上拷贝个图片过来,运行检测代码
python YOLO_tiny_tf.py -fromfile 000002.png

它这个图片只显示1秒就没有了, 是因为在main函数里,有一个cv2.waitKey(1000), 你可以改大一点就行了.
可以看到还是有一点效果的,只不过效果没有在darknet上做的效果好,估计darknet上面有处理吧,要想解释的话,还得去看yolov1的原生C语言代码,这里我就没细看了,因为只是做个实验.
检测(方法二)
因为之前研究yolo_tensorflow这个代码研究了很长时间,代码写的很好,想用他的这个代码和上面转换好的权重再做一次检测.代码写的很好,改的基本上是很少的.
主要改动两个文件yolo/config.py和yolo/yolo_net.py
yolo/config.py
- line 20: 把CLASSES改成CLASSES = [‘car’]
- line 34: CELL_SIZE = 11
- line 75: THRESHOLD = 0.1 #可以试一下0.2, 检测不出来,最大值也就0.1多
yolo/yolo_net.py
这里主要是把网络结构按照slim的格式改成tiny-yolo的结构,这个很简单:
def build_network(self,
images,
num_outputs,
alpha,
keep_prob=0.5,
is_training=True,
scope='yolo'):
with tf.variable_scope(scope):
with slim.arg_scope([slim.conv2d, slim.fully_connected],
activation_fn=leaky_relu(alpha),
weights_initializer=tf.truncated_normal_initializer(0.0, 0.01),
weights_regularizer=slim.l2_regularizer(0.0005)):
net = slim.conv2d(images, 16, 3, scope='conv_1')
net = slim.max_pool2d(net, 2, padding='SAME', scope='pool_2')
net = slim.conv2d(net, 32, 3, scope='conv_3')
net = slim.max_pool2d(net, 2, padding='SAME', scope='pool_4')
net = slim.conv2d(net, 64, 3, scope='conv_5')
net = slim.max_pool2d(net, 2, padding='SAME', scope='pool_6')
net = slim.conv2d(net, 128, 3, scope='conv_7')
net = slim.max_pool2d(net, 2, padding='SAME', scope='pool_8')
net = slim.conv2d(net, 256, 3, scope='conv_9')
net = slim.max_pool2d(net, 2, padding='SAME', scope='pool_10')
net = slim.conv2d(net, 512, 3, scope='conv_11')
net = slim.max_pool2d(net, 2, padding='SAME', scope='pool_12')
net = slim.conv2d(net, 1024, 3, scope='conv_13')
net = slim.conv2d(net, 1024, 3, scope='conv_14')
net = slim.conv2d(net, 1024, 3, scope='conv_15')
net = tf.transpose(net,(0,3,1,2))
net = slim.flatten(net, scope='flat')
net = slim.fully_connected(net, 256, scope='fc_16')
net = slim.fully_connected(net, 4096, scope='fc_17')
net = slim.dropout(net, keep_prob=keep_prob,
is_training=is_training, scope='dropout_18')
net = slim.fully_connected(net, num_outputs,
activation_fn=None, scope='fc_19')
return net
好了,再打开test.py文件,改一下权重路径和检测图片
权重路径
这里需要把上面转换好的YOLO_car_tiny.ckpt(三个文件)拷贝到data/weights目录下(本来是没有的,你创建一下就好了,你看他的README就是这样的)
修改代码:
line 168: parser.add_argument('--weights', default="YOLO_car_tiny.ckpt", type=str)
检测图片路径
line 185: 你从kitti拷贝一个来,做检测
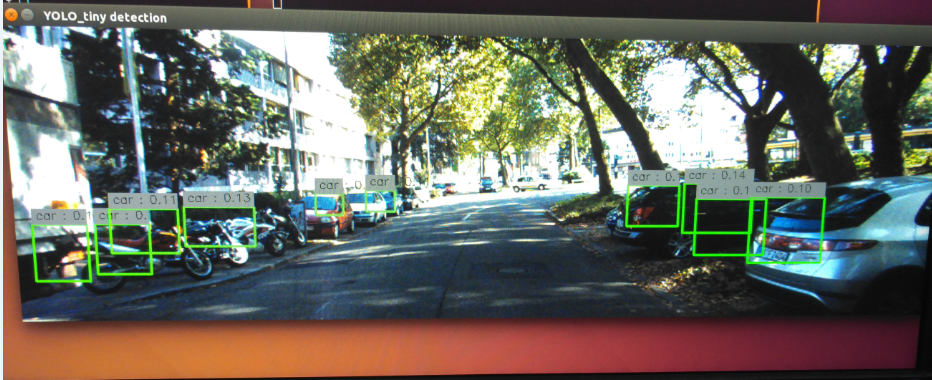
效果一般, 和刚才的一样.
……….
这里有一点需要说明一下, 也是困扰我很久的问题
看上面的网络, 在fc_16之前插了一句net = tf.transpose(net,(0,3,1,2)), 这是为什么呢?
一开始我没有这一句, 那检测的什么玩意, 根本就是瞎画. 后来我去看上面[检测方法一]中的代码,为什么它能检测出来呢, 就看到它的fc_layer里有一句判断:
if flat:
dim = input_shape[1]*input_shape[2]*input_shape[3]
inputs_transposed = tf.transpose(inputs,(0,3,1,2))
inputs_processed = tf.reshape(inputs_transposed, [-1,dim])
如果是需要展开,那你在展开之前需要transpose一下. 终于找到问题, 泪奔~~
后记
我也把我修改的代码上传上去,
yolo_weight_extractor
(对应上面的YOLO_tensorflow)
yolo_tensorflow_car(对应上面的yolo_tensorflow)
-
Previous
car detection using yolov1 -
Next
car classification using squeezeNet following deep compression