前言
用yolov2的tiny yolo版做car detection,主要还是参考官网的训练步骤,数据集还是用的kitti数据集,在我的这一篇博文里有提及
正文
数据集
还是先说数据集,数据集准备的主要思路还是:kitti->voc->yolo。因为有前人写好的工具,比较方便。
按照上篇博文里,将数据集都整理好(其实就是将所有的图像路径都存放到一个.txt文件中),比如我的train.txt里面的格式是:
/home/john/dockerData/darknetv2/data/voc/VOCdevkit/VOC2007/JPEGImages/007373.png
/home/john/dockerData/darknetv2/data/voc/VOCdevkit/VOC2007/JPEGImages/007375.png
/home/john/dockerData/darknetv2/data/voc/VOCdevkit/VOC2007/JPEGImages/007377.png
/home/john/dockerData/darknetv2/data/voc/VOCdevkit/VOC2007/JPEGImages/007380.png
...
修改cfg配置文件
按照官网来,进入darknet directory. 修改cfg/voc.data,这里我只做car detection,所以类只有一个
classes= 1
train = /home/john/dockerData/darknetv2/data/voc/2007_train.txt
valid = /home/john/dockerData/darknetv2/data/voc/2007_test.txt
names = data/voc.names
backup = backup #这个是输出的权重文件(比如tiny-yolo-voc_final.weights)存放的目录,会在当前目录创建一个叫backup的目录
然后修改data/voc.names,还是只留下一个car就行了
car
最后修改网络结构,这里我是在cfg/tiny-yolo-voc.cfg的基础上改的。主要贴一下最后边的region,这个region里面的anchors是在我自己的数据集上用KMeans生成的。这个后面会讲一下,也是参考别人的。
[region]
anchors = 0.40,0.94, 0.78,1.64, 1.43,2.51, 1.84,4.74, 3.01,5.78
bias_match=1
classes=1 #主要就是把这一个改了,因为是做一类检测
coords=4
num=5
softmax=1
jitter=.2
rescore=1
object_scale=1
noobject_scale=.5
class_scale=1
coord_scale=5
absolute=1
thresh = .6
random=1
还有一个需要跟据你最后的类别个数需要改的,就是最后一层convolutional的filter的个数,因为我是1类,所以改成30了。公式(5x(1+1+4) : 5个anchor,1个类别,1个confidence,4是(x,y,w,h))
训练
./darknet detector train cfg/voc.data cfg/tiny-yolo-voc.cfg darknet.conv.weights
这个darknet.conv.weights,我的前一篇博文也有说是怎么来的。
这样应该就可以训练了。最后会在backup文件夹下生成一个tiny-yolo-voc_final.weights文件
测试
./darknet detector test cfg/voc.data cfg/tiny-yolo-voc.cfg backup/tiny-yolo-voc_final.weights data/000002.png
验证
kitti提供了一个测评的代码,可以得到在测试集上的ap值。我用的是squeezeDet提供的检测代码。
这里想一下怎么检测,参考这个squeezeDet的实现,它是在python中调用的这个cpp文件,很巧,我们的darknet的作者也提供了python的接口。可以看一下examples/detector.py文件,里面有这么两句代码:
import sys, os
sys.path.append(os.path.join(os.getcwd(),'python/'))
import darknet as dn
可见,这个接口是在python/目录下,从这行代码也可以看出来调用的时候要在darknet的根目录下调用这个程序,也就是python examples/detector.py 。
再看一下python/darknet.py文件,在35行有一句:
35 lib = CDLL("libdarknet.so", RTLD_GLOBAL)
看的出,这个接口主要是根目录下的libdarknet.so的功劳,一开始不知道,后才想起,python安装的好像是.so结尾的文件。
OK,作者在examples/detector.py里面提供了可以使用的例子了,虽然很简单,但是修改修改也够用了,现在可以在python中调用了。接下来再将squeezeDet的kitti_eval代码拷贝到src/目录下,当然这个cpp代码还要修改一下,因为我做的是car detection,所以需要把它里面45,46行的”pedestrain”和”cyclist”注释掉,这样就可以用了。记得调用的时候是在根目录下调用:
python examples/detector.py
结果是在根目录下创建一个results文件夹,里面再创建一个data文件夹,data文件夹下会有ap曲线图。会显示3条线,分别是easy,middle,hard,这3个是3个等级,因为kitti数据集中会提供一些遮挡等级,拿easy来说,就是遮挡太严重(OCCLUSION=1,2)的就不算在ground_truth里面了。这样最后ap值就会高了。
K-means生成anchors
下面说一下Kmeans得到anchors,这里主要参考了hrsstudy的博文。基本上算是拷贝吧,人家写的非常好,不用改了。
kmeans算法概要
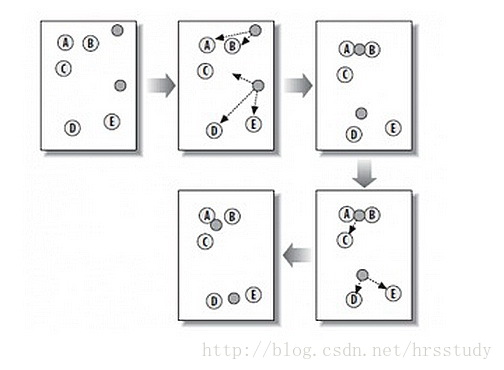 从上图中,我们可以看到,A, B, C, D, E 是五个在图中点。而灰色的点是我们的种子点,也就是我们用来找点群的点。有两个种子点,所以K=2。
从上图中,我们可以看到,A, B, C, D, E 是五个在图中点。而灰色的点是我们的种子点,也就是我们用来找点群的点。有两个种子点,所以K=2。
然后,K-Means的算法如下:
随机在图中取K(这里K=2)个种子点。 然后对图中的所有点求到这K个种子点的距离,假如点Pi离种子点Si最近,那么Pi属于Si点群。(上图中,我们可以看到A,B属于上面的种子点,C,D,E属于下面中部的种子点) 接下来,我们要移动种子点到属于他的“点群”的中心。(见图上的第三步) 然后重复第2)和第3)步,直到,种子点没有移动(我们可以看到图中的第四步上面的种子点聚合了A,B,C,下面的种子点聚合了D,E)。
k-means算法缺点
1、需要提前指定k 2、k-means算法对种子点的初始化非常敏感
kmeans++
k-means++是选择初始种子点的一种算法,其基本思想是:初始的聚类中心之间的相互距离要尽可能的远。
方法如下: 1.从输入的数据点集合中随机选择一个点作为第一个聚类中心 2.对于数据集中的每一个点x,计算它与最近聚类中心(指已选择的聚类中心)的距离D(x) 3.选择一个新的数据点作为新的聚类中心,选择的原则是:D(x)较大的点,被选取作为聚类中心的概率较大 4.重复2和3直到k个聚类中心被选出来 5.利用这k个初始的聚类中心来运行标准的k-means算法
第2、3步选择新点的方法如下:
a.对于每个点,我们都计算其和最近的一个“种子点”的距离D(x)并保存在一个数组里,然后把这些距离加起来得到Sum(D(x))。
b.然后,再取一个随机值,用权重的方式来取计算下一个“种子点”。这个算法的实现是,先用Sum(D(x))乘以随机值Random得到值r,然后用currSum += D(x),直到其currSum>r,此时的点就是下一个“种子点”。原因见下图:

假设A、B、C、D的D(x)如上图所示,当算法取值Sum(D(x))*random时,该值会以较大的概率落入D(x)较大的区间内,所以对应的点会以较大的概率被选中作为新的聚类中心。
k-means 计算 anchor boxes
根据YOLOv2的论文,YOLOv2使用anchor boxes来预测bounding boxes的坐标。YOLOv2使用的anchor boxes和Faster R-CNN不同,不是手选的先验框,而是通过k-means得到的。 YOLO的标记文件格式如下:
<object-class> <x> <y> <width> <height>
bject-class是类的索引,后面的4个值都是相对于整张图片的比例。 x是ROI中心的x坐标,y是ROI中心的y坐标,width是ROI的宽,height是ROI的高。
卷积神经网络具有平移不变性,且anchor boxes的位置被每个栅格固定,因此我们只需要通过k-means计算出anchor boxes的width和height即可,即object-class,x,y三个值我们不需要。
由于从标记文件的width,height计算出的anchor boxes的width和height都是相对于整张图片的比例,而YOLOv2通过anchor boxes直接预测bounding boxes的坐标时,坐标是相对于栅格边长的比例(0到1之间),因此要将anchor boxes的width和height也转换为相对于栅格边长的比例。转换公式如下:
w=anchor_width*input_width/downsamples
h=anchor_height*input_height/downsamples
例如: 卷积神经网络的输入为416*416时,YOLOv2网络的降采样倍率为32,假如k-means计算得到一个anchor box的anchor_width=0.2,anchor_height=0.6,则:
w=0.2*416/32=0.2*13=2.6
h=0.6*416/32=0.6*13=7.8
距离公式
因为使用欧氏距离会让大的bounding boxes比小的bounding boxes产生更多的error,而我们希望能通过anchor boxes获得好的IOU scores,并且IOU scores是与box的尺寸无关的。 为此作者定义了新的距离公式:
d(box,centroid)=1−IOU(box,centroid)
在计算anchor boxes时我们将所有boxes中心点的x,y坐标都置为0,这样所有的boxes都处在相同的位置上,方便我们通过新距离公式计算boxes之间的相似度。
后记
上面的代码在我的github上可以找到
kmeans生成anchors
darknetv2_car_detection